

Oracle DBからエラーが発生――どうしたらいい?
0. はじめに
Oracle DBを運用しているうえで避けては通れないエラー調査。実際にエラーが発生した際に何を確認したらいいのかを、現場で実際に携わった経験を基にまとめてみました。
1. 何はともあれアラートログ確認
エラー発生を受け取った際、おそらく何らかの監視ツールからの発報で知ることが多いかと思います。そうなるとエラーの全容が分からない、ということでまずはアラートログの確認を行います。
アラートログにもいくつか種類があるため、注意して確認してください。
l DBのアラートログ
オーソドックスかつ基本のアラートログ。DBから発生したメッセージを確認できます。
l ASM (Automatic Storage Management)アラートログ
RAC環境であれば存在しており、ASMインスタンスから発生したメッセージを確認できます。
l CRS (Cluster Ready Services)アラートログ
こちらもRAC環境で存在しており、クラスタ内で発生したメッセージを確認できます。
2. アラートログの次は……
アラートログを確認した後はエラーと一緒に出力されているトレースログ、出力されていればインシデントログを確認しましょう。
〇トレース・ファイル
セッションの動作、エラーの詳細などを記録するためのファイルです。主に以下の用途で確認されます。
> 障害発生時の原因調査
> バックグラウンドプロセスのエラー確認
> Oracle サポートへの情報提供
また、ユーザーセッションとバックグラウンドプロセス(LGWR, DBWn, PMON など) それぞれにトレース・ファイルが作成されます。
深刻なエラー(ORA‑600、ORA‑7445 などの内部エラー)が発生した際に生成されるログです。エラー診断はインシデント発生時に関連情報が自動的に収集されます。これにより、問題解析やサポート依頼が容易になります。
ADRCIコマンドを使用することで、コマンドライン上で確認する方法もありますため、必要に応じて使い分けていきましょう。基本的にはインシデントログの収集で問題ないかと思います。
〇 ダンプ / コア・ファイル
ORA‑07445などOSエラーが発生した際に出力されるダンプファイルです。プロセスのメモリ情報がダンプされているため、SRを上げた際にエラー解析で求められることあるので収集しておきましょう。
これらのログはエラー解析に使用され、主にサポートへ情報を連携する際に求められます。サポートにこれらのログを送付してエラー解析は完了、とする前にこちらでも確認できる限り原因を解析してみましょう。
3. エラー調査の流れ
エラーについて知るために、まずはエラー番号でWeb検索してみます。今回は、流れを追いやすくするためORA-04031の例で考えてみましょう。
ORA-04031: unable to allocate XXXX bytes of shared memory
この空き領域が共有プールに存在しない場合に発生するため、SGA周りのメモリサイズが問題に見えます。メモリの問題を確認ため、AWR(もしくはSTATSPACK)を確認していきましょう。
まずは、以下の基本的な3項目を確認した後、他の項目の確認に移ります。
1. Top 10 Foreground Events
SQL実行中にセッションが待機した時間の長いイベントを確認できます。待機時間が多い順に10個のイベントが表示され、データベースの性能問題(CPU、I/O、ロック、ネットワークなど)の改善ポイントを特定するための指標になります。
2. Instance Efficiency Percentages (Target 100%)
Oracleインスタンスの内部リソースがどれくらい効率的に働いているかを確認できます。
Load Profile同様、どこに問題が潜んでいるかの当たりをつけることができます。
3. Load Profile
データベースの基本的な負荷状況(トランザクション量、CPU消費、ブロック読み書き量など)を1秒あたり、もしくは1トランザクションあたりで確認できます。他の項目を確認する前にLoad Profileを確認することで、どこに問題があるかの当たりをつけることができます。
さらに、今回の事例ではメモリ関係のエラーだということで、以下のパラメータを確認していきます。
〇 Memory Dynamic Compornents
各SGA内のコンポーネントのサイズが確認できます。
共有プールの割り当ては、DEFAULT buffer cacheから割り当てられるため、この値が枯渇していないことを確認します。DEFAULT buffer cacheは初期化パラメータdb_cache_sizeで指定したサイズは予約されており、割り当てができないサイズであることに注意してください。
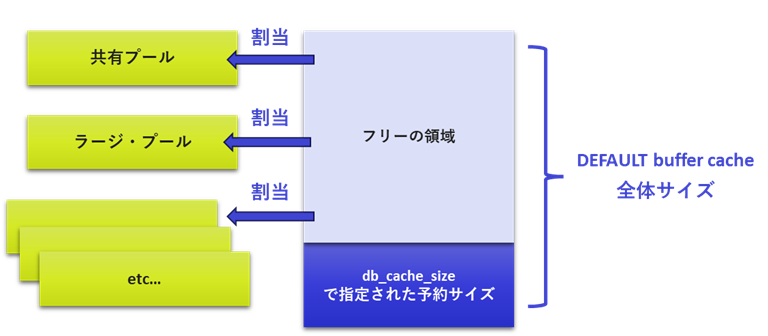
また、Last Op Typ/Mod列から拡張要求が発生したタイミングを確認することで、システム内のいつ動いた処理がメモリを使用しているかが確認できます。
〇 SQL ordered by Elapsed Time、Getsなど
Memory Dynamic Compornentsで確認したメモリを使用しているタイミングで、特に負荷をかけたSQLを確認します。Elapsed Timeで実行時間の長いSQLを、Getsで論理読み込み量が多いSQLを確認することで、原因特定をしていきます。
今回の事例、ORA-04031エラーでは特にMemory Dynamic Compornentsを確認することで、直接原因の特定がほぼできると思いますが、根本原因の改善方法としては、定期的なDB再起動やSGAサイズの見直しなどが必要になるかと思います。
もっと詳しく原因について確認する場合はインシデントファイルを確認し、解析していく必要が出てきます。例えば共有プール枯渇が原因であった場合、共有プールはいくつかのサブプールからできているのですが、どのサブプールが原因かを確認することで障害時の内部動作が鮮明になり、根本原因の改善としてより有効な手段を確認することができるかもしれません。これらの解析については、より専門的になりますため別の機会で連携できればと思います。
AWRはメモリだけに限らず、様々なエラー解析で活躍しますので、アラートログを確認したらAWRを確認してみるという流れは、大体のエラー調査において辿る道になるかと思います。
AWRの確認の勘所はエンジニアそれぞれであるため、今回紹介したフローはあくまで一例となります。
4. その他、障害調査で確認する
AWRの他にもエラー調査で活躍する情報は以下になります。
〇 ASH(Active Session History)
AWRよりも細かく性能分析ができるツールです。以下の情報を細かく確認することができます。
> セッションがどの時刻にアクティブだったか
> 何を実行していたか(SQL、PL/SQL)
> CPU を使っていたのか、待機していたのか
> 発生している待機イベントはあるか
V$ACTIVE_SESSION_HISTORYビュー、DBA_HIST_ACTIVE_SESS_HISTORYビューに情報は記録されます。
> V$ACTIVE_SESSION_HISTORY
1秒ごとのセッション情報が記録されますが、メモリ上に記録されるためインスタンス再起動などで情報が消えます。また、長時間は参照できません。
> DBA_HIST_ACTIVE_SESS_HISTORY
10秒ごとのセッション情報が記録されます。保持期間はAWRと同様のため、過去の事象を確認することに利用されます。
〇 TFA(Trace File Analyzer)
Oracle が提供する障害調査・パフォーマンス解析用の診断データ収集ツールです。エラーが発生した際にサポートから取得を求められるため、インストールできる環境であればインストールしておくことをお勧めします。
> OS、Database、Clusterwareなどのログを自動で一括収集
> 時間範囲や対象DBを指定して必要な情報だけ集める
> Oracle サポートに提出するための情報を 1コマンド で取得できる
5. まとめ
普段は障害発生のタイミングで取得している情報について、筆者の実体験で培った確認フローを紹介しました。今回紹介したフローが絶対というわけではないのですが、現場のエンジニアの方々は、紹介した内容だけでなくプラスアルファをもって障害時に調査をされていると思います。 以下に今回ご紹介したフローを図にしたものを記載しますため、お役に立てれば幸いです。
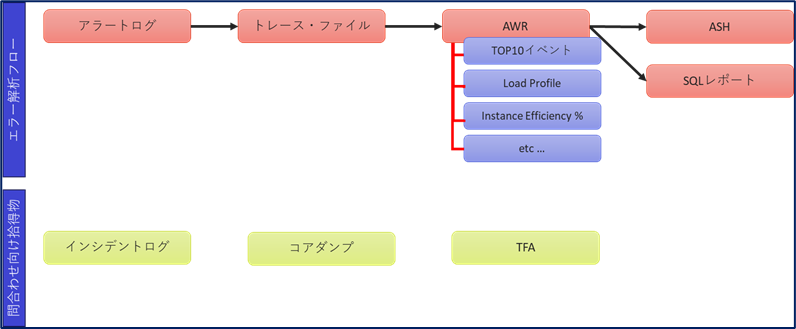
昨今OCIなどのクラウドが注目されていますが、維持管理という分野でこのような切り分けは現場からは消え難いかと思いますため、各人の障害調査フローなどをまとめておくといざというときに役に立つかと思います。
こちらの発言は全て個人的意見です。内容につきましては、十分注意し投稿しておりますが、誤りがあれば直接ご指導頂けますとありがたいです。
6. CNSについて
CNSではAIをビジネスに活用するコンサルティング、AIを活用したデータ分析・データ利活用などを支援しています。
AIの活用にご興味のある方は、お気軽にご相談下さい。
▶ お問い合わせフォームはこちら:
https://reg34.smp.ne.jp/regist/is?SMPFORM=ofte-lerand-a156f4b7d094ddf7db06c166e8de81dd



