

【Amazon EKS】Terraformを使ったEKSバージョンアップ手順
本記事では、Terraformを使ったEKSバージョンアップの手順を紹介いたします。
IaCでEKS環境を運用している、もしくはバージョンアップさせたいと考えている方々の一助となればと思います。
はじめに
今回は、コード化されたEKSを想定し、Terraformで構築されたEKSの、クラスタ及びノードグループのバージョンアップの手順をご紹介いたします。
はじめに、EKSの簡単な説明をします。特に必要ない方は、次の「注意点」からお読みください。
EKSとは「Amazon Elastic Kubernetes Service」の略で、AWS上でKubernetesを利用できるようにしたマネージド型サービスです。
Kubernetesとは、コンテナ化されたアプリケーションの管理、スケーリング、デプロイを自動化するオープンソースシステムです。AWS上のコンテナサービスには他にECSがありますが、EKSにはオープンソースをAWSに移管できるという特徴があります。
EKSは、約4か月に一度、新しいマイナーバージョンがリリースされます。
マイナーバージョンは、リリースされてから14ヶ月は標準サポート対象となり、その後1年間の延長サポート対象となります。
現在のEKSリリースとサポート期限は、AWSの公式ドキュメント(以下リンク)から確認できます。
注意点
手順紹介の前に、いくつか注意点を記載いたします。
- 本記事で紹介するバージョンアップ方法では、EKS上のpodの停止と、ノードグループの再作成を伴うため、EKS自体の停止が必要になります。
- 記載している手順、画面キャプチャは2024年9月時点のものになります。今後、AWSコンソールのアップデートにより、記載している手順、及び画面キャプチャと実際の作業手順が一致しない場合がございます。予めご了承ください。
- 今回紹介する手順は、弊社で実際にEKSバージョンアップ(1.25→1.28)を行った際の手順を基にしております。
- 本記事は、EKSおよびノードグループのバージョンアップについて記載しております。「Kubectlやkustomize等のコントロールプレーンのバージョンアップ」「 アドオンのバージョンアップ」については記載しておりません。
- EKS(Kubernetes)は、バージョンアップによって旧機能が廃止、変更されることがありますが、本記事では特定のバージョンでの旧機能廃止、変更の対応方法を記載しておりません。実際にEKSのバージョンアップを行う際は、AWSやKubernetesの公式ドキュメントより、廃止や変更される機能を確認した上でバージョンアップを実施してください。
- バージョンアップ実施前に、対象のEKSにて「ノード名」「ノード上のpod名」「Namespace名」を確認してください。それぞれの情報はコマンド実行時に利用します。各名称はAWSコンソール上のEKSクラスターのリソース情報から確認が可能です。
バージョンアップ手順
Terraformで構築したEKSを対象としているためtfvarsファイルを編集・適用するだけで、バージョンアップを実現することを想定しています。
Terraformを使ったEKSの構築方法については、下記公式ドキュメントをご確認ください。
バージョンアップの全体的な流れは以下になります。
- ノードのdrain
- tfvarsファイルの修正
- tfvarsファイルの適用
ノードのdrain
まず、EKSのバージョンアップを行う前に、EKS上のノードを停止させ、Podを退去、および終了させます。
バージョンアップ前にEKS上のPodを退去・終了させておかないと、バージョンアップ中にPodの退去失敗(PodEvictionFailure)によって、バージョンアップが上手くいかなくなる場合があります。
(私がバージョンアップ検証をした際には、このことを知らず、ここでかなり詰まりました...)
ノードを停止させるため、以下コマンドを実行します。
「kubectl drain」コマンドを実行することで、指定したノード上のpodを終了させられ、なおかつ、そのノード上に自動でpodが立たないようにすることができます。
オプションの意味は以下になります。
| オプション |
意味 |
|---|---|
--ignore-daemonsets |
DaemonSetのpodがあっても続行する。
ノード上でDaemonSetで管理されているPodがある場合、
このオプションをつけないとコマンドがエラーとなりdrainできない。
|
--force |
ReplicaSetなどを使わずに単体で起動しているPodがノード上にあっても続行する。
ノード上に該当podがある場合、
このオプションをつけないとコマンドがエラーとなりdrainできない。
|
--delete-emptydir-data |
emptyDir (ノードがドレインされると削除されるローカル データ) を
使用しているポッドがある場合でも続行する。
|
上記コマンドを実行すると、実行中のpodが退去(evict)されます。基本的には、このコマンドでノードを停止させます。
実行結果として以下が表示されたら、ノードが停止した=drainされたことになります。
ただ、上記コマンド実行した際、一部podは下記のエラーが出て、podを退去できず、結果としてノードの停止(drain)が完了しない場合があります。
上記のエラーは、対象のPodを移動できないことを意味します。
この事象は、PodDisruptionBudget(PDB)という停止できるPodの最大数を決める設定値が原因です※1。
そちらの設定を変更することでもこのエラーは解消可能ですが、今回は設定変更はせず、podを指定して手動で終了させ、その後にpodを退去させます。
Podの終了コマンドは以下になります。
以下が表示されれば、Podが終了してます。
(コマンド実行時の実際の出力例です。一つずつ終了させてますが、スペースでpod名を区切ると複数podを同時にdelete可能です)

Podが終了したら、再度上記のノードdrainコマンド(kubectl drain <ノード名> ~~)を実行し、ノードのdrainを確認します。
EKS上のすべてのノードのdrainが完了したら、以下のコマンドでpodの稼働状況を確認します。
すべてのpodのSTATUSがpendingになっていることを確認します(RESTARTSやAGEの内容は一例です)。
※1:参考資料は以下になります↓
tfvarsの修正
tfvarsファイルを修正します。
Kubernetes_versionの値を一つ上のバージョン※に書き変えます。
※本手順では、EKSとノードグループのバージョンアップを同時に行うことになります。
EKSは一気にバージョンを上げることができない(例:1.25→1.27といったバージョンアップはできず、1.25→1.26→1.27とバージョンアップする必要がある)ため、バージョンは現行のものの一つ上のバージョンを記載してください。
tfvarsファイルの修正および保存が完了したら、init、plan(以下コマンド)を実行し、エラーが出ないこと、及び変更箇所が想定通りであることを確認します。
参考ですが、以下のようにtfvarsファイルを編集します。
<terraform.tfvars_修正前(一部抜粋した例)>
<terraform.tfvars_修正後(一部抜粋した例)>
tfvarsの適用
以下コマンドで、tfvarsを適用させます。
tfvarsの内容を環境に適用することを確認されます。
ノードグループのバージョン等、変更点が想定通りであれば「yes」を入力してください。
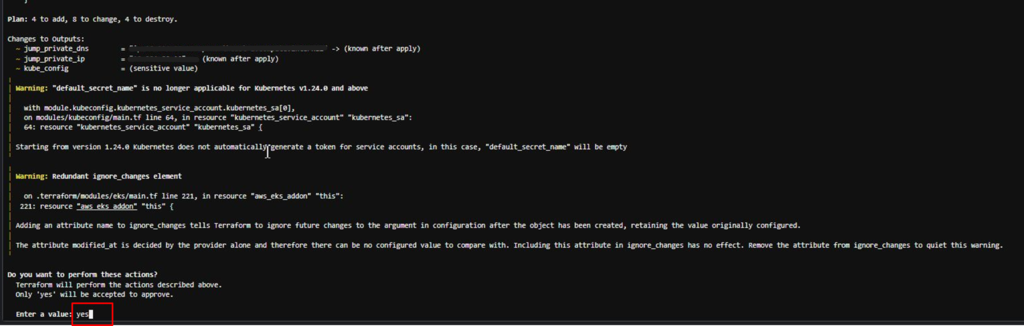
ほどなくしてEKSのバージョンアップが始まります。
EKSのバージョンアップが終わり次第(実際にやってみたときは10~15分程度でした)、ノードグループのバージョンアップに移り、ノードグループのバージョンアップも何事もなく終われば、「Apply complete!」と出力され、適用完了となります。

以下コマンドで、EKSのバージョンが上がったことが確認できます。
実際にコマンドを実行してみると、以下のように出力されます(ROLEやAGE、VERSIONの内容は一例です)。
VERSIONの列で、各ノードのバージョンが確認できます。
先述したpodの稼働確認コマンドで、podが正常に起動していることを確認します。
※podが起動するまでの時間にはばらつきがあります。
まとめ
以上、コードベースでのEKSバージョンアップ手順についてまとめてみました。
改めて全体的な流れをおさらいしますと、①ノードのdrain、②tfvarsファイルの修正、③tfvarsファイルの適用といった流れになります。
私自身、tfvarsファイルの修正と適用だけでバージョンアップ可能かと検証前は思っておりましたが、実際にはノード上のpodのことも気にかける必要があったようです。
皆様の困りごと解消の手助けになれば幸いです。
CNSでは、AWSを始めOCI、Azure、GCP等を用いたクラウドシステムの構築、複数クラウドを組み合わせたハイブリッド・マルチクラウド構成、さらにはサーバレス、コンテナ、マイクロサービス等の構築が可能です。
各種クラウドの活用に興味のある方は是非、お気軽にお問合せ下さい。



